Closing the visibility gap between cloud-native networks and cloud infrastructure

The myth about cloud-native networks is that they don’t have any hardware dependencies. With all the benefits—and there are many—that cloud-native networking brings, it’s easy to forget that there’s a physical infrastructure below the cloud. And while assurance and closed-loop orchestration solutions work to keep the network running optimally, server and software infrastructure issues may go undetected by these systems—but not the customer.
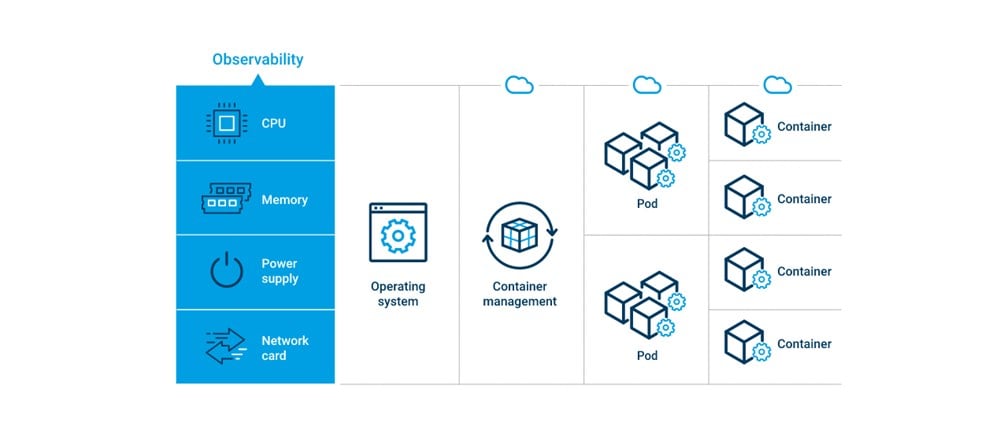
Cloud-native networking introduces a new fault domain—the cloud infrastructure—and this domain, for the most part, is invisible to the network and service operations teams. We call this the ‘visibility gap’.
Traditionally, there are four distinct operations teams, each operating independently, for the most part. From a telco perspective, there are the network operations team and service operations team. As their names suggest, they look after the health of the network (in this case, the virtual network) and the customers, respectively.
Leveraging traditional telco quality of service (QoS) metrics and key performance indicators (KPIs), the network operations (NetOps) team strives to keep the network running at optimal levels.
Leveraging traditional telco quality of experience (QoE) metrics and key quality indicators (KQIs), the service operations (SrvcOps) team strives to keep the customer services running optimally.
Leveraging traditional IT observability metrics (traces, logs and alerts), the IT operations (ITOps) team strives to keep the server infrastructure running optimally while the cloud operations (CloudOps) team works to keep the cloud software (Kubernetes, Linux OS, etc) running optimally.
The challenge is that these teams often work in organizational silos, which makes it difficult to share information and see the big picture. This issue is compounded by the fact that the tools and metrics the telco and IT/cloud operations teams use are different—in effect, the teams speak different languages.
To help resolve this dilemma, EXFO worked closely with Intel to incorporate Intel® Platform Telemetry Insights into EXFO’s adaptive service assurance (ASA) platform. The ASA platform leverages advanced, telco machine learning (ML) algorithms for automated anomaly detection and correlation, effectively closing the gap between the cloud-native network and services layers and the cloud infrastructure layers. By having this integrated and fully correlated view of the network, all four operations teams can see exactly how issues in their own domain impact—or are impacted by—issues in other domains, closing the visibility gap and helping to break down the administrative silos that can get in the way of fault resolution and hurt the customer experience.
This is what we call full-stack assurance.
The noisy neighbor problem
Nobody likes a noisy neighbor, and the same holds true for cloud-native networks. So, what exactly is a noisy neighbor? Today’s servers are built on multi-core CPUs which allow multiple workloads to execute concurrently, thus making better use of space and power, as well as better utilization of memory, cache, and I/O resources, which may not be fully utilized by a single workload. All this means that servers can continue to do more, in less space and use less power.
However, there can be unintended consequences for packing things so tightly and sharing resources. Today’s servers can have up to 128 distinct processor cores per CPU. Half of these cores will be hyperthreaded instances—a single core running 2 different workloads—and these physical cores will share some resources, such as L1 cache, with adjacent cores.
The noisy neighbor situation arises when one workload impacts another workload through resource sharing—or should we say resource hogging. The challenge for the service provider (SP) is that even after you take the time to isolate the server, core and Kubernetes workload associated with a degraded condition, you may not realize that it’s a ‘neighboring’, unassociated workload causing the degraded condition to happen.
But with the enhanced visibility provided by full-stack assurance, the ASA platform can detect degradations in a customer’s QoE, correlate that degradation back to issues detected in a specific server, correlate those and other relevant issues and ‘see’ the impact that other workloads are having on the degraded service—in other words, find the noisy neighbor.
And by automating the detection, correlation and analysis of the noisy neighbor condition, it can automatically forward the insight to the appropriate team or orchestrator to rectify the issue. Additionally, as QoE can be measured edge-to-core and cloud servers also span the network edge-to-core, this solution delivers service and network assurance from infrastructure to customer experience and end-to-end!


