The role of test orchestration in service lifecycle orchestration

Communications service provides (CSPs) are well on their way to digitally transforming their operations processes. The fundamental business drivers behind this transformation are the need to dramatically increase agility by reducing time to market for new products and services, as well as reducing the cost to deploy and maintain these new services. It’s also well acknowledged that the new services, enabled by 5G, ultra-reliable low latency communications (URLLC) and massive machine type communications (mMTC), will quickly overwhelm traditional operations methods and that automation, and eventually autonomous operations will be essential to supporting scalability and profitable growth.
To achieve this transformation, CSPs are actively investigating and implementing digitally transformed operations platforms that leverage automation to address the need for speed, agility and cost reduction. Technologies like virtualization, SDN, AI and Orchestration combined with open ecosystems like TMF ODA, MEF LSO, Linux Foundation ONAP and various ETSI standards are playing a key role in enabling this transformation.
And while these industry ecosystems have come a long way in defining open architectures, standard interfaces and data models to enable this agility and automation, up until now, this activity has been mainly focused on the automation of ‘day-one’ operations. However, we know from experience that the automation of day-one operations is only part of the process. It’s in the rest of the service life cycle (assuring quality, resilience and availability) where most of the operational cost resides.
At the heart of this ‘beyond day-one’ activity is test orchestration. An orchestrated, open and intelligent infrastructure for testing, monitoring and troubleshooting is a key enabler to automation and closed-loop policies. Our experience has shown us that a massive volume of data, produced by the network infrastructure, is not enough to drive actionable assurance, and that post-event analysis of this non-real-time data is an expensive way to identify performance anomalies. Instead, an independent assurance and monitoring solution with knowledge of both customer-facing key quality indicators (KQIs), i.e., the service intent, and network-facing key performance indicators (KPIs) can deliver a more efficient and effective way of discovering such violations. By having knowledge of both the service intent and the technology underlying the service, a test activation center can build test blueprints for each service to deliver the KPIs and KQIs specified in the service definition, without the service designer needing to know how they are created (see Figure 1 ).
First step to automate is discovery
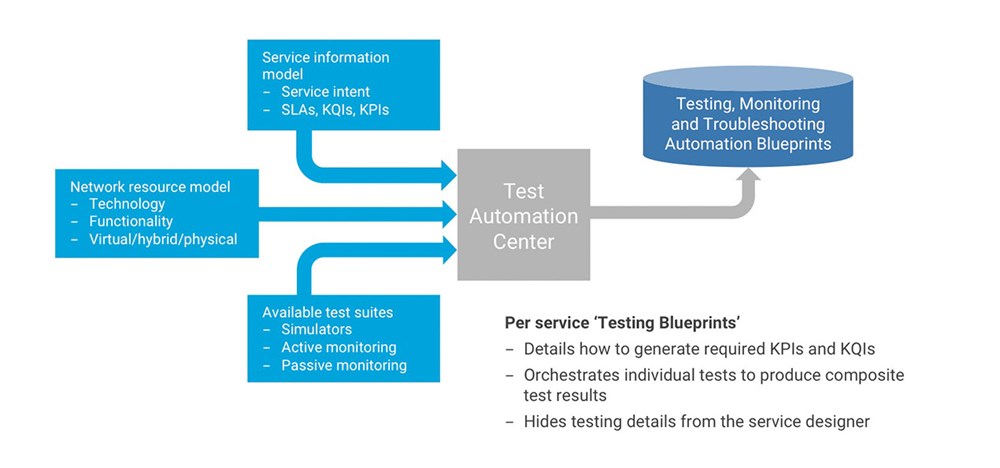
Figure 1: Test, monitoring and troubleshooting blueprints
To support the goal of an open network ecosystem, our vision here at EXFO is to provide a rich portfolio of open, orchestrated test, monitoring and troubleshooting tools that includes embedded simulation capabilities, along with active and passive monitoring capabilities, all enriched by automatic topology discovery to address the highly dynamic nature of virtual networks. The integration of these capabilities with the service and domain orchestrators through rich open API has the following benefits:
- Hides all the implementation details of testing and monitoring from the BSS system
- Provides a consistent set of testing, monitoring and troubleshooting capabilities throughout the entire service lifecycle, which may span more than one technology lifecycle
- Agnostically supports both virtualized and legacy/ hybrid networks with the same data models and APIs, enabling easy migration of resources without changing customer-facing products and services.
- Supports closed-loop and service assurance policies with actionable data derived in real-time from testing and troubleshooting network and service resources
Of course, the best automation is automation that also enables agility. To support both automation and agility, you need to start at the service design phase. Service intent and data modeling at the design phase is fundamental to automating the generation of test and monitoring blueprints. It’s through these blueprints that you can meet the following objectives:
- The automatic mapping of service intent to network resource-specific testing and monitoring procedures so that it hides domain-level technology details
- Enables product managers to design services without specific knowledge or understanding of how to map service intent to domain/resources specific monitoring procedures, thereby allowing them to quickly design new services that may span several different technology domains
- Changes in service intent can quickly and automatically be translated into changes in domain specific monitoring and automation procedures
- Similarly, changes in domain technology and/or resources can be quickly and automatically be translated into changes in automation procedures to continue supporting service intent
Second step to automation is open API
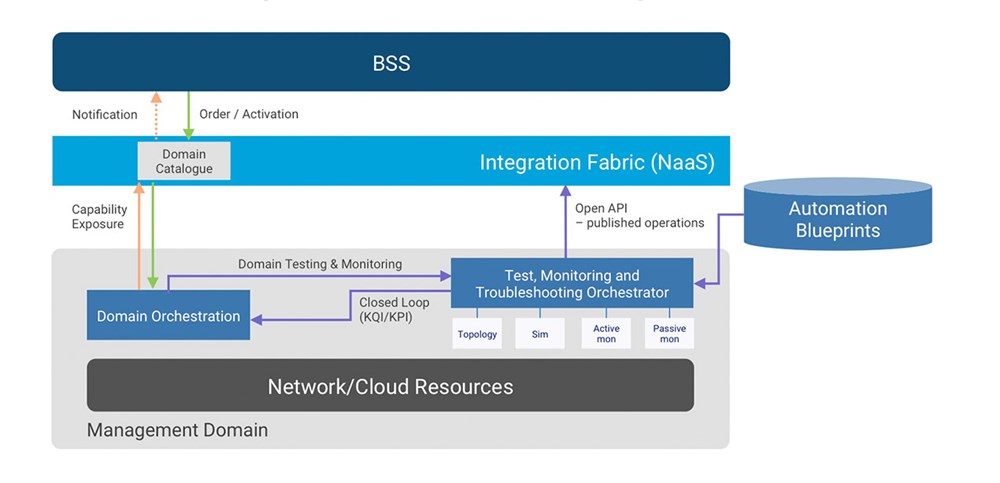
Figure 2: Run-time orchestration
As networks continue to virtualize and automation takes on a bigger role in service lifecycle management, the role of testing and monitoring becomes even more critical, essentially becoming the nervous system of the autonomous operations systems. As shown in Figure 2, test orchestration will be key in abstracting test functionality away from domain-specific details of executing test and monitoring functions to derive the KPIs and KQIs needed to manage a service. By only exposing high-level test functionality through standard, open APIs, product managers can design new services quickly, without having to understand the underlying technology, and test infrastructure upgrades can be implemented without impacting service delivery.


