What do service providers need to see and do to keep customers connected in disruptive times?
By Mae Kowalke
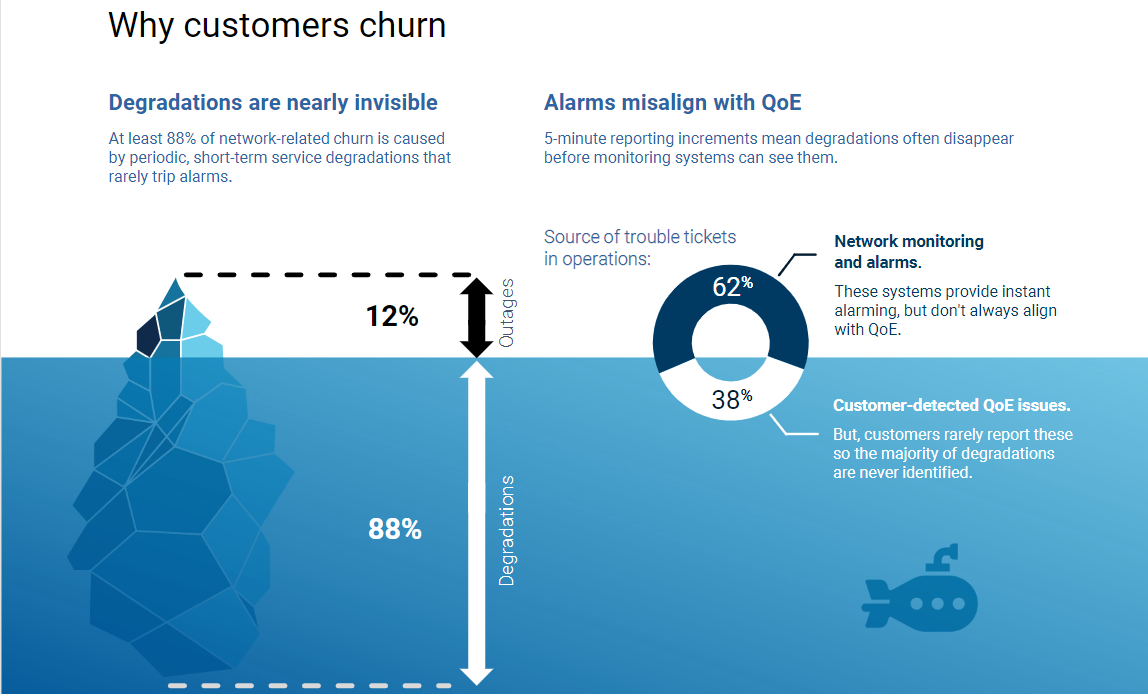
Here’s a truth that cannot be ignored: telecom service degradations cause 88% of network-related churn, compared with 12% for outages (Heavy Reading 2019). This effect is amplified for service providers during disruptive times—like traffic being up 30-50% globally during the COVID-19 pandemic (GSMA April 2020)—when customers are most heavily dependent on telecom services.
Customers being forced into new routines causes network traffic to spike in locations and at times otherwise relatively quiet. The population turns to social media, voice and video calls to check on loved ones and establish response plans with their employers. Remote working and streaming video consumption drive high utilization in residential areas. And despite the increased traffic, networks aren’t crashing completely, they are slowing in fits and starts: the perfect ‘degradation’ scenario.
Although customers are less likely than normal to switch providers during major disruptions (GSMA predicts mobile churn could be below 10% for 2020), once the immediate crisis is over there is likely to be a spike in churn among users who experienced poor service when they needed it most. Conversely, customers who got what they needed when they needed it are likely to become more loyal. It’s interesting to note that 49% of a customer’s brand loyalty is determined by their network experience.
Obviously, it is in everyone’s interest for telecom services to work well even when conditions are not normal. For service providers, the challenge is that most degradations are invisible to traditional monitoring systems, so they are alerted only if customers report them. In operations, 38% of trouble tickets originate from customer-detected quality of experience (QoE) issues (Heavy Reading 2019). But customers rarely report these issues; instead, they tolerate short-term impairments 100 times more often than they call to complain (Heavy Reading 2019).
However, abnormal traffic patterns do trip off seas of alarms that overwhelm operations staff who may be working remotely themselves with limited access to vital data and collaboration tools. Under such conditions, the logical strategy is to prioritize resolving issues affecting critical services, customer groups, and the largest number of customers.
But, to do so effectively requires understanding the relationship between impacted customers, alarms, and possible root causes. Unfortunately, that often is not possible either because monitoring systems cannot detect issues in real-time or because QoE impact misaligns with alarms. For example, many degradations disappear too fast for 5-15 minute reporting intervals to see them, and less than two-thirds (62%) of operations trouble tickets originate from monitoring and alarms to begin with (Heavy Reading 2019). This leads to significant service issues going undetected and unaddressed.
Systems and processes that require a lot of ongoing human setup and intervention contribute to these problems. Even under normal circumstances, detecting degradations with alarms is hard since it relies on manually defining thresholds. Getting a clear view of user impact requires analyzing hundreds of unique categories of call data records (CDRs). This is a time-consuming big-data problem inherent with traditional monitoring systems.
The way of the future—or now—is to instead use real-time stream processing, coupled with machine learning-based anomaly detection. This eliminates the need for thresholds and collapses big data overhead to automatically create cases for subscribers with common problems, such as call drops or slow data speeds. Cases can then be grouped if they have a common root cause. And, operations can stop relying on call center tickets to identify otherwise difficult-to-detect issues.
Having that level of granular visibility is a great improvement over the common scenario where, using traditional monitoring and assurance tools, it takes an average of 12 people from 3 teams more than 3 hours to find the root cause of impairments (Heavy Reading 2019).
Being able to quickly identify the most important issues and what action to take is useful not only during times of disruption but also for applications in the coming 5G era. New applications bring traffic density and dynamic performance demands from machine-to-machine (M2M) communication and applications using network slices—mimicking many of the characteristics unfolding during times of crisis.
EXFO’s SensAI uses machine learning to derive significantly more insight from existing systems, enabling operations to resolve issues faster and deliver an excellent quality of experience to drive loyalty, subscriber count, and margin. This makes it possible not only to maintain control in challenging times but also have insurance for what’s about to come.